


今天小千要給大家分享一道關(guān)于數(shù)據(jù)庫緩存同步的面試題,希望通過這道面試題可以幫助大家搞定面試官。

一. 數(shù)據(jù)緩存
數(shù)據(jù)緩存在高并發(fā)的系統(tǒng)設(shè)計(jì)中很常見,因?yàn)镽edis確實(shí)能有效地解決數(shù)據(jù)庫和磁盤的I/O瓶頸,當(dāng)一個(gè)高并發(fā)接口要查詢低頻修改的數(shù)據(jù)時(shí),我們都建議用Redis實(shí)現(xiàn)數(shù)據(jù)緩存。
一般的緩存實(shí)現(xiàn)思路如下:
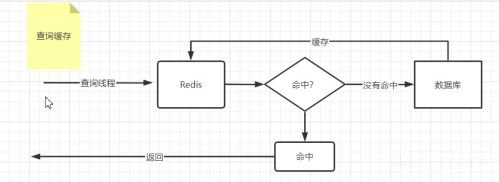
其實(shí)緩存的實(shí)現(xiàn)思路很簡單,這個(gè)思路能保證只有第一次查詢的是數(shù)據(jù)庫,后續(xù)的訪問查詢的都是Redis,這樣不僅提高了接口的訪問效率,還在一定程度上實(shí)現(xiàn)了數(shù)據(jù)庫的讀寫分離。
那么現(xiàn)在問題來了,如果我們的數(shù)據(jù)庫數(shù)據(jù)發(fā)生了變化,Redis怎么保證和數(shù)據(jù)庫里的數(shù)據(jù)一致呢?這個(gè)問題就是我們今天要探討的緩存同步問題。
二. 緩存同步分析
緩存同步這個(gè)思路相信大家很快就能搞清楚,大概思路如下:
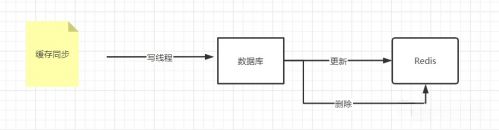
當(dāng)我們對業(yè)務(wù)庫做了修改,我們可以通過同步更新的方式去同步,也可以通過暴力刪除Redis的方式去同步。因?yàn)閯h除Redis,會再次查詢數(shù)據(jù)庫的最新數(shù)據(jù),這樣就可以達(dá)成同步的目的。但不管你使用哪種方式,都會存在一些意想不到的問題,如下:
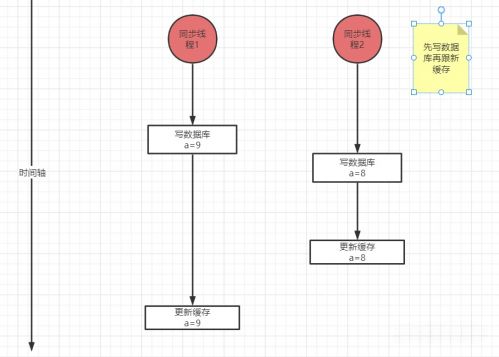
先寫數(shù)據(jù)庫,再更新Redis,上圖中演示了一種極端情況,按照時(shí)間軸的發(fā)展,數(shù)據(jù)庫里的最新值是8,但Redis中的最新值是9,并沒有一致。
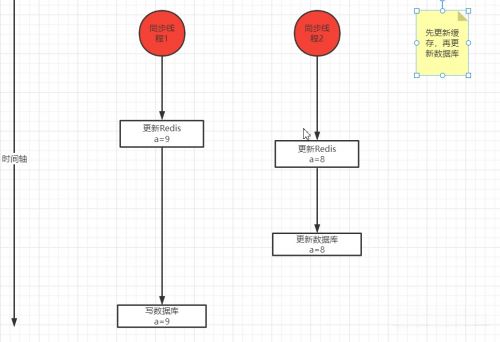
如果我們先更新Redis,再寫數(shù)據(jù)庫,按照時(shí)間軸,Redis里的最新值是8 ,數(shù)據(jù)庫里的最新值是9,還是沒有保持一致。
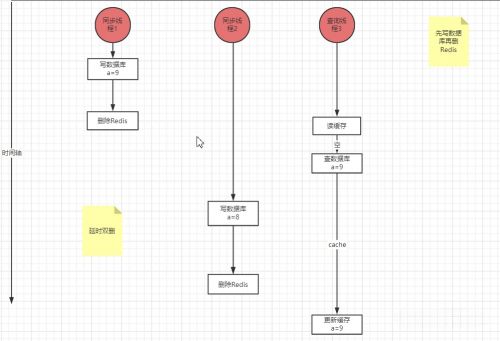
先寫數(shù)據(jù)庫,再刪Redis,這也不行。
如上圖,當(dāng)數(shù)據(jù)庫里的值為9,然后再刪Redis。假如這時(shí)有一個(gè)讀線程來了,發(fā)現(xiàn)Redis數(shù)據(jù)沒了,這個(gè)讀線程立即查詢數(shù)據(jù)庫,讀到的就是9。然而不巧的是另外一個(gè)寫線程將數(shù)據(jù)庫改為8 ,也就是說數(shù)據(jù)庫最新為8,結(jié)果緩存發(fā)生在更新數(shù)據(jù)庫之后,緩存最新的值就是9,還是不能一致。
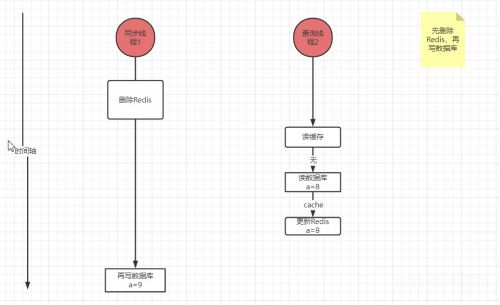
如果我們先刪Redis再寫數(shù)據(jù)庫,寫線程上來把Redis刪了,讀線程立即讀數(shù)據(jù)庫,比如讀到的舊數(shù)據(jù)是8,然后寫線程再改數(shù)據(jù)庫為9,這時(shí)數(shù)據(jù)庫最新為9,但Redis中的值是8,結(jié)果還是不一致。
三. 緩存同步解決思路
上面分析了四種情況,它們在極端情況下都不能保證數(shù)據(jù)庫和Redis的雙寫一致性,那到底為什么不能呢?問題到底出在哪里了,其實(shí)原因很簡單,就是我們不能保證數(shù)據(jù)庫和redis操作的原子性!在我們進(jìn)行這兩個(gè)操作時(shí),總是有別的線程在破壞數(shù)據(jù),所以才會出現(xiàn)各種問題,那怎么解決呢?我們先來看看下面的解決思路:
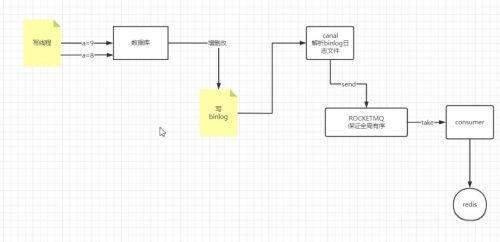
這個(gè)思路大致是這樣的,寫線程只負(fù)責(zé)改數(shù)據(jù)庫,不要去參與Redis同步的問題,Redis同步交給一個(gè)嚴(yán)格順序的pipeline解決。這個(gè)pipeline的流程是,當(dāng)數(shù)據(jù)庫發(fā)生數(shù)據(jù)變化會立即產(chǎn)生binlog日志,我們可以借助阿里的canal組件去監(jiān)聽binlog,同時(shí)解析binlog,將解析的結(jié)果以消息的方式發(fā)送給MQ。MQ要保證嚴(yán)格順序,再通過消費(fèi)者去消費(fèi)消息,將最新的數(shù)據(jù)覆蓋更新到Redis,到此就能解決緩存的同步。
現(xiàn)在你對數(shù)據(jù)庫和Redis緩存的同步問題還有疑惑嗎?如果還有別的問題,請關(guān)注我們吧,干貨不斷哦。













 京公網(wǎng)安備 11010802030320號
京公網(wǎng)安備 11010802030320號