


各位朋友們,今天給大家帶來的是數據分析的內容。歡迎各位朋友多提寶貴意見哦!
本次分享給大家的是:DataFrame的多層索引及使用。
多層索引是指在行或者列軸上有兩個及以上級別的索引,一般表示一個數據的幾個分項。比如,下圖所示的數據樣式:
我們使用的是對美女的顏值投票數據,現在有幾位美女分別給他們起了容易記憶的名字,比如:小麗,小芳啊
于是拿著這些照片來到辦公區,投票啦!投票啦!大家分成了兩組進行投票,男生一組、女生一組,投票的內容就是:漂亮和不漂亮。
于是就有了下面的數據部分:
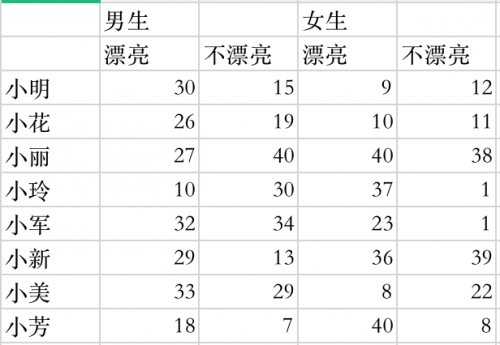
大家發現這個表格數據跟我們常用的不同,那就是列名是有兩層的。那這樣的數據怎么進行數據分析呢?
```
import numpy as np
import pandas as pd
beauty = pd.read_excel('beauty.xlsx')
beauty
```
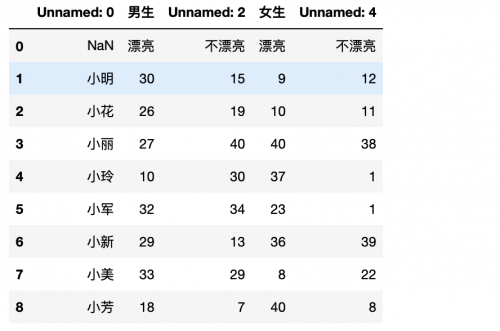
這是什么情況?列名怎么還有Unnamed:0,Unnamed:1這些呢?是我們讀取數據的時候沒有設置index_col和header屬性。
header設置的是列,如果是多列則使用列表,從左到右為0,1,2,...,index_col則是設置的行,用來指定行索引。
```
beauty = pd.read_excel('beauty.xlsx',header=[0,1],index_col=0)
beauty
```
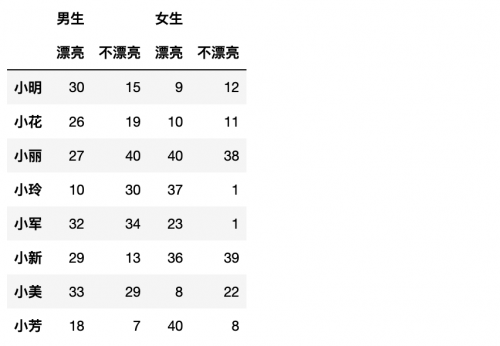
但是要自己創建一個多層索引則有兩種方式:分別是隱式和顯式的。
### 創建多層索引
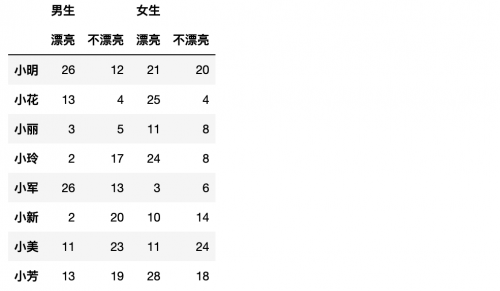
方法一:隱式創建,即給DataFrame的`index`或`columns`參數傳遞兩個或更多的數組。我們自己構建一個顏值投票的數據。
```
df1 = pd.DataFrame(np.random.randint(1,30, size=(8, 4)),
index= ['小明','小花','小麗','小玲','小軍','小新','小美','小芳'],
columns=[['男生', '男生', '女生', '女生'],
['漂亮', '不漂亮', '漂亮', '不漂亮']])
```
數據雖然有些區別,但是結構是一樣的。
方法二、顯示創建,推薦使用較簡單的`pd.MultiIndex.from_product`方法。
MultiIndex表示多級索引,它是從Index繼承過來的,其中多級標簽用元組對象來表示。from_product()從多個集合的笛卡爾積創建MultiIndex對象。
具體的詳解:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.MultiIndex.html
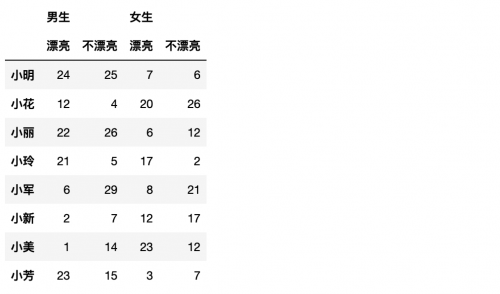
```
df = pd.DataFrame(np.random.randint(1,30, size=(8, 4)),
index= ['小明','小花','小麗','小玲','小軍','小新','小美','小芳'],
columns=pd.MultiIndex.from_product([['男生', '女生'],
['漂亮', '不漂亮']]))
```
哇!完美!比剛才的還簡單了呢?
### 檢索多層索引
如果檢索小美的女生投票如何獲取呢?再比如獲取小玲的男生漂亮值的投票數是多少呢?
我們一起來看看吧!我們以上面真實的投票數據為例來看一下
```
df.男生
```
結果:

小新的女生投票如何獲取呢?這時候就要使用loc[行,列]了,當然如果是小美則就是df.loc[‘小美’,'女生']

當然你也可以獲取前3位美女的女生投票,兩種方式loc和iloc均可以實現。
```
df.loc[['小明','小花','小麗'],'女生']
```
或者
```
df.iloc[0:3,[2,3]]
```

如果要獲取小明,小麗,小軍,小美的男女生的漂亮投票數呢?(可以評論區留言哦,我們一起學習有幾種獲取方式)
### 更改多層索引的層級
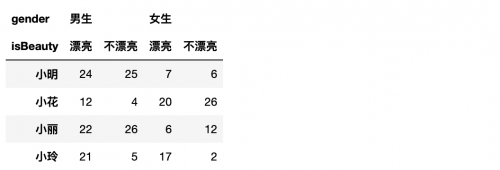
所謂更改多層索引的層級,就是交換下男女生和漂亮和不漂亮的位置。在交換之前我們要知道叫交換的層的名字,但是我們又沒有名字,所以我們就要先設置名字,然后交換。
```
df.columns.names = ['gender', 'isBeauty'] # 設置列索引名
# 如果設置index行索引,則可以下面的方式
# df.index.names = ['你的名字']
```
截取部分數據:
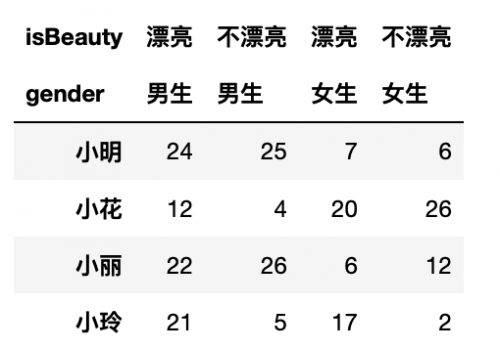
然后就可以交換啦!使用swaplevel

```
df.swaplevel('gender', 'isBeauty',axis=1) # 因為我們是交換列索引,所以axis=1
```
結果:
### 多級索引的值排序
索引名字排序
```
df.sort_index(level=0, axis=1, ascending=True) # 對列索引gender的值進行排列
```
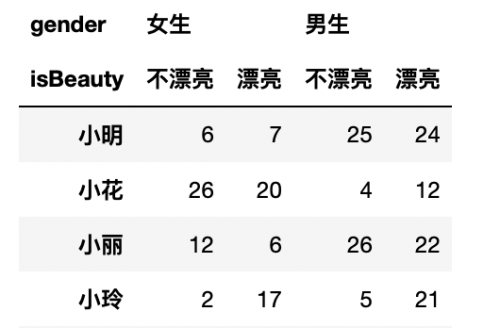
但是問題來啦!如果說按照男生的漂亮值降序排列如何實現?這就是多層索引的值排序啦!
```
df.sort_values(by=[('男生','漂亮')],ascending=False) # 注意觀察參數by的內容
```
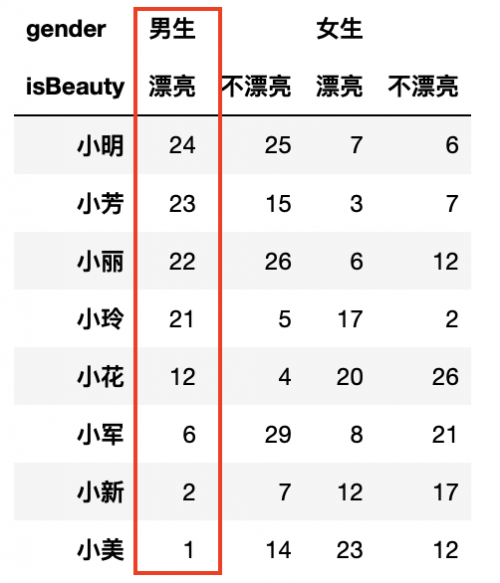
如果是按照女生不漂亮進行升序排列呢?
### 多級索引匯總統計
所謂匯總就是類似求和、求均值、最大值之類的。比如男生漂亮的最多票數是誰?男女生的漂亮數總和?
其實這個還是離不開我們常用的sum(),mean(),max(),min().....
```
df.sum(level=0,axis=1) # 男女生的票數總和,其中level指定了多層索引的索引值
```
或者
```
df.sum(level=1,axis=1) # 此時獲取的就是漂亮和不漂亮的總和
```
結果:
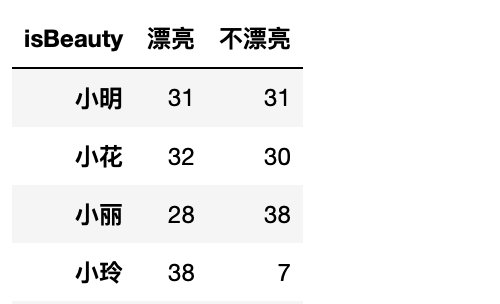
但是男生漂亮的最多票數是誰?這樣就是跨行獲取最大值
```
df.男生.漂亮.max()
```
所以很重要的就是:從求和這里我們來分析,就是我們是跨行求和還是跨列求和。跨行就是axis=0,跨列就是axis=1.
### 多級索引軸向轉換
常見的數據層次化結構:樹狀和表格
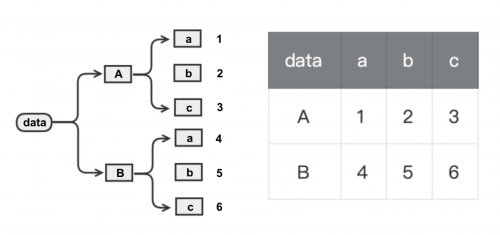
- 軸向轉換的函數
> 1. stack:“透視”某個級別的(可能是多層的)列標簽,返回帶有索引的 DataFrame,該索引帶有一個新的最里面的行標簽。
> 2. unstack:(堆棧的逆操作)將(可能是多層的)行索引的某個級別“透視”到列軸,從而生成具有新的最里面的列標簽級別的重構的 DataFrame。
>
> stack 過程將數據集的列轉行,unstack 過程為行轉列。
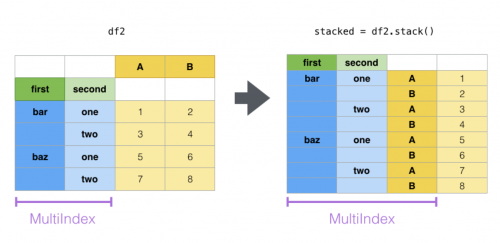
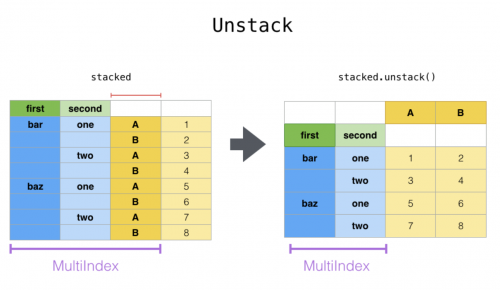
```
df1 = df.stack() # 默認是內層的進行轉換
df1
```
截取部分:
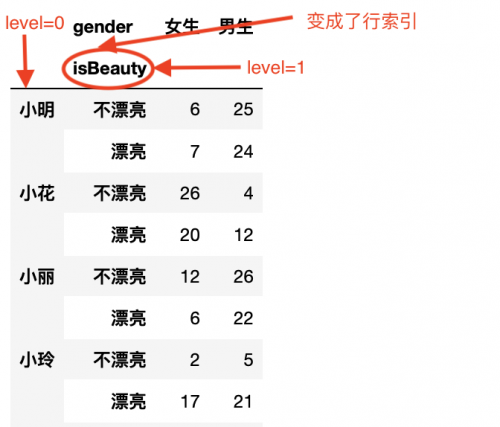
注意此時使用的是df1,df1是上圖轉換后的數據。按照上圖標記的level=0和level=1
```
df1.unstack(level=0) # 就是將level=0的數據轉換到列上
```

如果數據里面的缺失值,則可以使用dropna的參數即:df.stack(dropna=True)
另外還有一些屬性,比如:
> df.index.names 查看行索引的名稱
>
> df.columns.names 查看列索引的名稱
>
> df.index.nlevels 層級數
>
> df.index.levels 行的層級
>
> df.columns.levels 列的層級
>
> df[['男生','女生']].index.levels 篩選后的層級
>
> df.index.droplevel(0) 刪除指定等級
希望本篇文章可以給大家帶來收獲,如果喜歡的話,歡迎轉發哦!















 京公網安備 11010802030320號
京公網安備 11010802030320號