


累加器和廣播變量在哪些場景使用?累加器是分布式的并且共享只寫變量。如果在轉換運算符中調用了累加器,并且沒有后續的動作運算符,則不會執行累加器。如果后面兩次調用action操作符,累加器會被執行兩次,導致過度加法。

1、廣播變量的使用介紹
解決的場景:
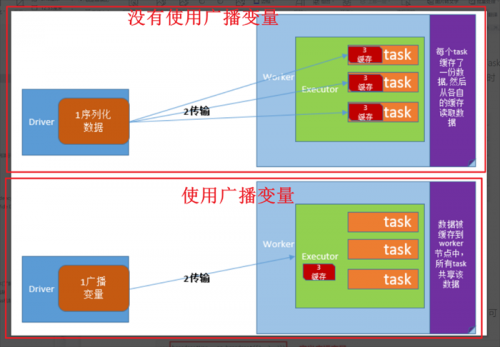
將Driver進程的共享數據發送給所有子節點的Executor進程的每個任務。如果不使用廣播變量技術,Driver端默認會將共享數據分發給各個[Task],對網絡分發造成很大壓力。
如果采用廣播變量技術,Driver端的共享數據只會發送給每個[Executor]。 Executor 中的所有任務都重用這個對象。確保共享對象是[可序列化的]。因為跨節點傳輸的數據必須是可序列化的。
將共享對象廣播到Driver端的每個Executor:
val bc = sc.broadcast(共享對象)
在執行器中獲得:
bc.值
2、累加器的使用方法
集群中的所有 Executor 對同一個變量執行累積操作。 Spark 目前只支持累加 [add] 操作。內置3個累加器:【LongAccumulator】、【DoubleAccumulator】、【CollectionAccumulator】。
如何使用整數累加器?
在Driver端定義整數累加器并賦初值。
acc=sc.accumulator(0)
Executor端每次累加1
acc+=1
或者 acc.add(1)
3、綜合案例


以上代碼不僅練習了累加器和廣播變量在哪些場景使用,還練習了如何使用函數式編程(Map、Filter),如何創建上下文變量,以及如何使用并行性。這些練習比較全面,希望能幫助你學習更多技能。更多關于IT大數據培訓的問題,歡迎咨詢千鋒教育在線名師,如果想要了解我們的師資、課程、項目實操的話可以點擊咨詢課程顧問,獲取試聽資格來試聽我們的課程,在線零距離接觸千鋒教育大咖名師,讓你輕松從入門到精通。














 京公網安備 11010802030320號
京公網安備 11010802030320號