


什么是Scrapy
Scrapy是一個為了爬取網站數據,提取結構性數據而編寫的應用框架。
框架就是將平常寫爬蟲的request (異步調度和處理)、下載器(多線程的 Downloader)、解析器(selector)和 twisted(異步處理)封裝到了一起,夠成了框架。而且使用起來更加方便,爬取速度更快。
Scrapy框架的應用領域有很多,例如網絡爬蟲開發、數據挖掘、自動化測試等,其最初是為了頁面抓取(網絡抓取)所設計的,也可以應用在獲取API所返回的數據或者通用的網絡爬蟲。官方網址是https://scrapy.org/
Scrapy的安裝
Windows系統:
pip install scrapy
如果安裝過程中出錯
錯誤信息如下:
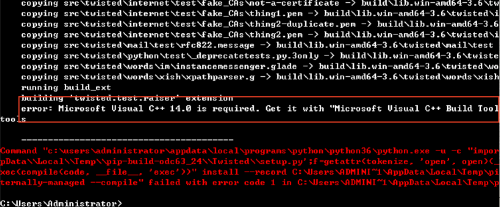
則需要安裝Microsoft Visual C++14,如果報錯不是Microsoft Visual C++14比如Microsoft Visual C++15則對應安裝即可。
如果安裝過程中過提示安裝Twisted安裝失敗,則需要來到這個網址:https://www.lfd.uci.edu/~gohlke/pythonlibs/自行下載wheel文件,

可能需要下載的是:pyOpenSSL、Twisted、PyWin32,可以根據安裝時,報錯的提示信息有針對性的下載。
下載之后放到一個固定的目錄中,進入下載的目錄。執行 pip3 install xxxxxx.whl (注意xxxxxx代表的是你下載的wheel的名字)
然后再次執行:pip install scrapy
Linux和mac系統直接:pip3 install scrapy
scrapy工作流程
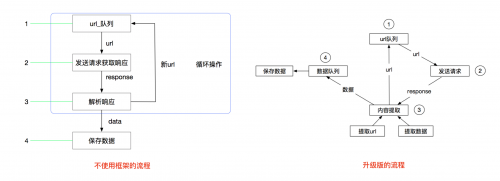
Scrapy工作流程的圖:
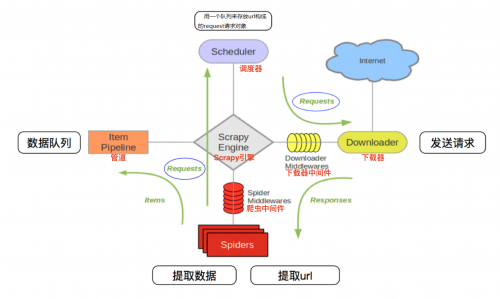
在圖中,Scrapy引擎是架構的核心部分,調度器、管道、下載器和Spiders等組件都通過引擎來調控。在Scrapy引擎和下載器中間通過中間件傳遞信息,在下載中間件中,可以插入自定義代碼擴展Scrapy的功能,例如實現IP池的應用。引擎和Spiders之間也是通過爬蟲中間件來傳遞信息,同樣可以自定義擴展功能。
其中:
Scrapy引擎負責控制整個數據處理流程,處于整個Scrapy框架中心位置,協調調度器、管道、中間件、下載器、爬蟲。
調度器負責存儲等待爬取的網址,確定網址優先級,相當于一個隊列存儲,同時也會過濾一些重復的網址。
下載器實現對等待爬取的網頁資源進行高速下載,該組件通過網絡進行大量數據傳輸,下載對應的網頁資源后將數據傳遞給Scrapy引擎,再由引擎傳遞給爬蟲處理。
下載中間件用于處理下載器與Scrapy引擎之間的通信,自定義代碼可以輕松擴展Scrapy框架的功能
Spiders是實現Scrapy框架爬蟲的核心部分。每個爬蟲負責一個或多個指定的網站。爬蟲組件負責接收Scrapy引擎中的Response響應,接收到響應后分析處理,提取對應重要信息
爬蟲中間件是處理爬蟲組件和Scrapy引擎之間通信的組件,可以自定義代碼擴展Scrapy功能
管道用于接收從爬蟲組件中提取的管道,接收到后進行清洗、驗證、存儲等系列操作
因此其流程可以描述如下:
爬蟲中起始的url構造成request對象-->爬蟲中間件-->引擎-->調度器
調度器把request-->引擎-->下載中間件--->下載器
下載器發送請求,獲取response響應---->下載中間件---->引擎--->爬蟲中間件--->爬蟲
爬蟲提取url地址,組裝成request對象---->爬蟲中間件--->引擎--->調度器,重復步驟2
爬蟲提取數據--->引擎--->管道處理和保存數據
每部分的具體作用

scrapy常用命令
scrapy后面可以跟不同的命令,可以使用scrapy --help進行查看,Scrapy框架中命令分為全局命令和項目命令,全局命令不需要進入Scrapy項目即可在全局中直接運行,項目命令必須在Scrapy項目中才可以運行。
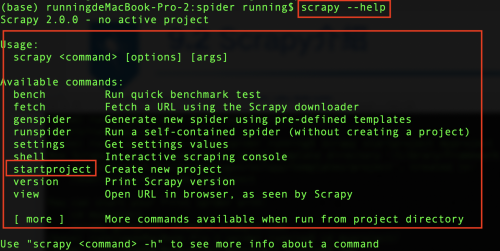
其中:
全局命令:
fetch命令是用來檢查spider下載頁面的方式
runspider命令通過Scrapy中的runspider命令可以直接運行一個爬蟲文件
settings命令是用來獲取Scrapy的配置信息。
shell命令可以啟動Scrapy的交互終端
version命令用于查看Scrapy的版本信息
項目命令:
Scarpy的項目命令主要有bench、check、crawl、edit、genspider、list、parse。Scrapy全局命令可以在項目內外使用,而項目命令只能在Scrapy爬蟲項目中使用。
bench命令可以測試本地硬件的性能。
genspider命令可以創建Scrapy爬蟲文件,這是一種快速創建爬蟲文件的方法
check命令可以實現對爬蟲文件的測試
crawl命令可以啟動某個爬蟲
list命令可以列出當前可使用的爬蟲文件
parse命令可以獲取指定的URL網址,并使用對應的爬蟲文件分析處理
scrapy開發步驟
創建項目:
scrapy startproject 爬蟲項目名字
生成一個爬蟲:
scrapy genspider <爬蟲名字> <允許爬取的域名>
提取數據:
根據網站結構在spider中實現數據采集相關內容
保存數據:
使用pipeline進行數據后續處理和保存
創建項目
使用Scrapy創建一個爬蟲項目,首先需要進入存儲爬蟲項目的文件夾,例如在“D:\python_spider”目錄中創建爬蟲項目,如圖所示。

當然如果你是Linux或者mac系統也需要進入存儲爬蟲項目的文件夾,然后新建項目

創建之后的爬蟲項目myproject目錄結構如下:
項目名字/
scrapy.cfg:
項目名字/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
scrapy.cfg 項目的主配置信息。(真正爬蟲相關的配置信息在settings.py文件中)
items.py 設置數據存儲模板,用于結構化數據,如:Django的Model
pipelines 數據持久化處理
settings.py 配置文件,如:遞歸的層數、并發數,延遲下載等
spiders 爬蟲目錄,如:創建文件,編寫爬蟲解析規則
生成一個爬蟲spider
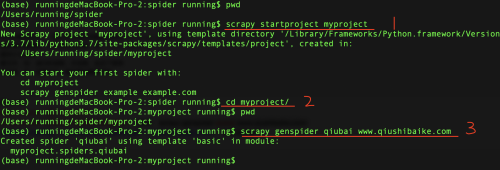
進入剛才創建的爬蟲項目myproject目錄

然后執行: scrapy genspider 應用名稱 爬取網頁的起始url (見下圖的3部分)
編寫爬蟲
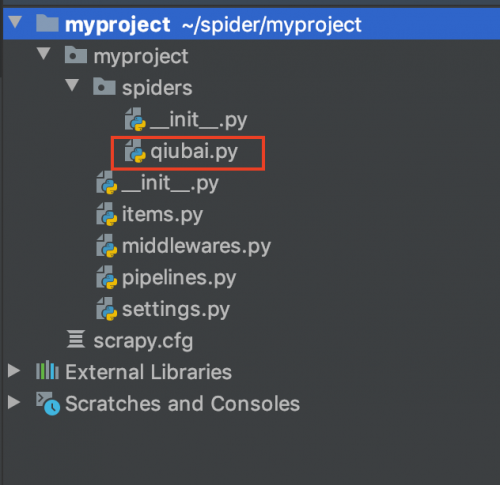
在生成一個爬蟲執行完畢后,會在項目的spiders中生成一個應用名的py爬蟲文件
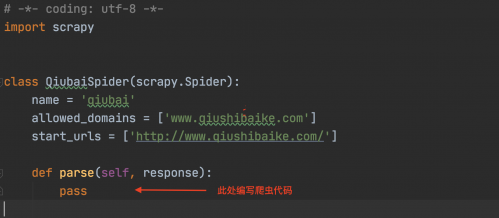
打開文件進行代碼編寫,大家看到的是默認的格式,可以在parse方法中完善爬蟲代碼
保存數據
數據的保存需要使用管道pipline,在pipelines.py文件中定義對數據的操作
定義一個管道類
重寫管道類的process_item方法
process_item方法處理完item之后必須返回給引擎

然后在settings.py配置啟用管道
ITEM_PIPELINES = {
'myproject.pipelines.MyprojectPipeline': 400,
}
配置項中鍵為使用的管道類,管道類使用.進行分割,第一個為項目目錄,第二個為文件,第三個為定義的管道類。
配置項中值為管道的使用順序,設置的數值約小越優先執行,該值一般設置為1000以內。
運行scrapy
命令:在項目目錄下執行scrapy crawl <爬蟲名字>
示例:scrapy crawl qiubai

當然本次只是給大家描述了一下爬蟲中使用scrapy的基本步驟,20天學會爬蟲后面會接連介紹scrapy的使用,敬請期待哦!















 京公網安備 11010802030320號
京公網安備 11010802030320號