


極驗給大家簡單介紹一下:https://www.geetest.com/,在這里給大家提供了智能組合、滑塊驗證、點選驗證的體驗。
滑塊驗證就是其中一部分,而像B站、斗魚、簡書、小米、汽車之家等都是他的客戶。如果大家感興趣也可以去其他網站試試,再次強調B站我還是很喜歡的
滑塊驗證碼簡述
有爬蟲,自然就有反爬蟲,就像病毒和殺毒軟件一樣,有攻就有防,兩者彼此推進發展。而目前最流行的反爬技術驗證碼,為了防止爬蟲自動注冊,批量生成垃圾賬號,幾乎所有網站的注冊頁面都會用到驗證碼技術。其實驗證碼的英文為 CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart),翻譯成中文就是全自動區分計算機和人類的公開圖靈測試,它是一種可以區分用戶是計算機還是人的測試,只要能通過 CAPTCHA 測試,該用戶就可以被認為是人類。由此也可知道破解滑塊驗證碼的關鍵即是讓計算機更好的模擬人的行為,這也是破解的難點所在。
配置環境
環境要求:
安裝Python3
pip install selenium pillow
selenium 安裝完成后,下載所選瀏覽器的 webdriver,這個前面一篇文章已經介紹過,不再重復介紹(注意下載的ChromeDriver版本需與Chrome瀏覽器版本對應)
破解步驟
思路分析:
利用selenium進入滑塊驗證碼頁面,截取所需頁面圖片。
通過圖片像素對比分析獲取缺口位置與滑塊移動距離。
機器模擬人工滑動軌跡。
難點分析:
這類驗證碼可以使用 selenium 操作瀏覽器拖拽滑塊來進行破解,難點兩個,一個如何確定拖拽到的位置,另一個是避開人機識別(反爬蟲)。
首先我們先看看,確定滑塊驗證碼需要拖拽的位移距離
有三種方式
• 人工智能機器學習,確定滑塊位置
• 通過完整圖片與缺失滑塊的圖片進行像素對比,確定滑塊位置
• 邊緣檢測算法,確定位置
各有優缺點。人工智能機器學習,確定滑塊位置,需要進行訓練比較麻煩,所以我們主要看后面兩種。
對比完整圖片與缺失滑塊的圖片
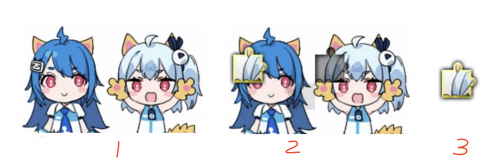
B站的滑塊驗證模塊,一共有三張圖片:完整圖、缺失滑塊圖、滑塊圖,都是由畫布canvas繪制出的。類似于:
下面三張圖:
HTML截圖如下:
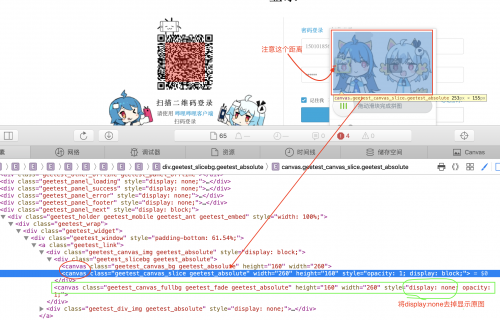
只需要通過selenium獲取畫布元素,執行js拿到畫布像素,遍歷完整圖和缺失滑塊圖的像素,一旦獲取到差異(需要允許少許像素誤差),像素矩陣x軸方向即是滑塊位置。另外由于滑塊圖距離畫布坐標原點有距離,還需要減去這部分距離。最后使用 selenium 拖拽即可。
部分代碼如下(結合selenium完成):
# 屏幕截圖
def get_screenshot(self):
"""
獲取網頁截圖
:return: 截圖對象
"""
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
x, y = screenshot.size
screenshot.resize((int(x / 2), int(y / 2)), Image.ANTIALIAS).save('screenshot.png')
screenshot = Image.open('screenshot.png')
return screenshot
# 計算驗證碼圖片所在的位置
def get_position(self):
"""
獲取驗證碼位置
:return: 驗證碼位置元組
"""
top = self.browser.execute_script("return document.documentElement.scrollTop")
print(top)
img = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'geetest_canvas_bg')))
print(img)
location = img.location
size = img.size
top, bottom, left, right = location['y'] - top, location['y'] - top + size['height'], location['x'], \
location['x'] + size['width']
return (top, bottom, left, right)
# 該動作會調用兩次,分別獲取原圖和帶缺口的圖
def get_geetest_image(self, name='captcha.png'):
"""
獲取驗證碼圖片
:return: 圖片對象
"""
top, bottom, left, right = self.get_position()
print('驗證碼位置', left, top, right, bottom)
screenshot = self.get_screenshot()
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha
# 獲取缺口的尺寸
def get_gap(self, image1, image2):
"""
獲取缺口偏移量
:param image1: 帶缺口圖片
:param image2: 不帶缺口圖片
:return:
"""
left = 60
print(image1.size[0])
print(image1.size[1])
for i in range(left, image1.size[0]):
for j in range(image1.size[1]):
if not self.is_pixel_equal(image1, image2, i, j):
left = i
return left
return left
# 比較兩張截圖的不同
def is_pixel_equal(self, image1, image2, x, y):
"""
判斷兩個像素是否相同
:param image1: 圖片1
:param image2: 圖片2
:param x: 位置x
:param y: 位置y
:return: 像素是否相同
"""
# 取兩個圖片的像素點
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 60
if abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(
pixel1[2] - pixel2[2]) < threshold:
return True
else:
return False
邊緣檢測算法,確定位置
滑塊基本上是個方形,通過算法確定方形起始位置即可。

滑塊是方形的,存在垂直與水平的邊,該邊在缺失滑塊圖中基本都是灰黑的。遍歷像素找到基本都是灰黑的邊即可。這種實現方式會存在檢測不出或錯誤的情況,使用時需要換一張驗證碼。也可能存在檢測出的邊是另一條(因為B站的滑塊不是長方形,存在弧形邊),那么需要減去滑塊寬度。
代碼如下(結合selenium完成):
class VerifyImageUtil():
def __init__(self):
self.defaultConfig = {
"grayOffset": 20,
"opaque": 1,
"minVerticalLineCount": 30
}
self.config = copy.deepcopy(self.defaultConfig)
def updateConfig(self, config):
for k in self.config:
if k in config.keys():
self.config[k] = config[k]
def getMaxOffset(self, *args):
# 計算偏移平均值最大的數
av = sum(args) / len(args)
maxOffset = 0
for a in args:
offset = abs(av - a)
if offset > maxOffset:
maxOffset = offset
return maxOffset
def isGrayPx(self, r, g, b):
# 是否是灰度像素點,允許波動offset
return self.getMaxOffset(r, g, b) < self.config["grayOffset"]
def isDarkStyle(self, r, g, b):
# 灰暗風格
return r < 128 and g < 128 and b < 128
def isOpaque(self, px):
# 不透明
return px[3] >= 255 * self.config["opaque"]
def getVerticalLineOffsetX(self, bgImage):
bgBytes = bgImage.load()
x = 0
while x < bgImage.size[0]:
y = 0
# 點,線,灰度線條數量
verticalLineCount = 0
while y < bgImage.size[1]:
px = bgBytes[x, y]
r = px[0]
g = px[1]
b = px[2]
if self.isDarkStyle(r, g, b) and self.isGrayPx(r, g, b) and self.isOpaque(px):
verticalLineCount += 1
else:
verticalLineCount = 0
y += 1
continue
if verticalLineCount >= self.config["minVerticalLineCount"]:
# 連續多個像素都是灰度像素,直線,認為需要滑動這么多
# print(x, y)
return x
y += 1
x += 1
完整步驟
本案例采用的是邊緣檢測算法。
步驟一:啟動selenium,獲取驗證碼圖片,方便查看預覽
from selenium import webdriver
import time
import base64
from PIL import Image
from io import BytesIO
from selenium.webdriver.support.ui import WebDriverWait
def checkVeriImage(driver):
# 等待畫布加載完畢
WebDriverWait(driver, 5).until(
lambda driver: driver.find_element_by_css_selector('.geetest_canvas_bg.geetest_absolute'))
time.sleep(1)
# 獲取有缺口的圖片
im_info = driver.execute_script(
'return document.getElementsByClassName("geetest_canvas_bg geetest_absolute")[0].toDataURL("image/png");')
# 得到base64編碼的圖片信息
im_base64 = im_info.split(',')[1]
# 轉為bytes類型
im_bytes = base64.b64decode(im_base64)
with open('./tempbg.png', 'wb') as f:
# 保存圖片到本地,方便查看預覽
f.write(im_bytes)
image_data = BytesIO(im_bytes)
bgImage = Image.open(image_data)
# 計算offsetx的長度
offsetX = VerifyImageUtil().getVerticalLineOffsetX(bgImage)
# 獲取滑塊按鈕
eleDrag = driver.find_element_by_css_selector(".geetest_slider_button")
action_chains = webdriver.ActionChains(driver)
# 拖動滑塊按鈕,注意滑塊距離左邊有 5~10 像素左右誤差
action_chains.drag_and_drop_by_offset(eleDrag,offsetX-10,0).perform()
貌似沒有問題了,但是總是出現這句話:拼圖被怪物吃掉了,請重試。這是因為被檢測到機器人(爬蟲)操作了。所以我們滑動的動作要更像我們人為的行為。如何避開人機的識別?分析原因是:webdriver.ActionChains(driver).draganddropbyoffset(eleDrag,offsetX-10,0).perform() 拖動滑塊動作太快了的緣故。當然期間宋宋也這樣實現過:
action_chains = webdriver.ActionChains(driver)
action_chains.click_and_hold(slider).perform()
action_chains.pause(0.2)
ran = random.randint(1,50)
action_chains.move_by_offset(xoffset=distance - ran, yoffset=0)
action_chains.pause(0.6)
action_chains.move_by_offset(xoffset=ran-10, yoffset=0)
action_chains.pause(0.5)
action_chains.move_by_offset(xoffset=4, yoffset=0)
action_chains.pause(0.4)
action_chains.move_by_offset(xoffset=5, yoffset=0)
action_chains.pause(0.6)
action_chains.move_by_offset(xoffset=1, yoffset=0)
action_chains.pause(0.6)
action_chains.release()
action_chains.perform()
就是慢點實現多拖動幾次并且加入了休眠,但是這么做還是不會成功的,仍然會提示:拼圖被怪物吃掉了,請重試
稍微改進一下(使用了 actionchains.moveby_offset(10,0)用于修正):
action_chains = webdriver.ActionChains(self.driver)
# 點擊,準備拖拽
action_chains.click_and_hold(source)
action_chains.pause(0.2)
action_chains.move_by_offset(targetOffsetX-10,0)
action_chains.pause(0.6)
action_chains.move_by_offset(10,0)
action_chains.pause(0.6)
action_chains.release()
action_chains.perform()
但是驗證成功的概率也是挺低的。為了更像人類操作,可以進行拖拽間隔時間和拖拽次數、距離的隨機化,于是來個更加完美版。
def simulateDragX(self, source, targetOffsetX):
"""
模仿人的拖拽動作:快速沿著X軸拖動(存在誤差),再暫停,然后修正誤差
防止被檢測為機器人,出現“圖片被怪物吃掉了”等驗證失敗的情況
:param source:要拖拽的html元素
:param targetOffsetX: 拖拽目標x軸距離
:return: None
"""
action_chains = webdriver.ActionChains(self.driver)
# 點擊,準備拖拽
action_chains.click_and_hold(source)
# 拖動次數,二到三次
dragCount = random.randint(2, 3)
if dragCount == 2:
# 總誤差值
sumOffsetx = random.randint(-15, 15)
action_chains.move_by_offset(targetOffsetX + sumOffsetx, 0)
# 暫停一會
action_chains.pause(self.__getRadomPauseScondes())
# 修正誤差,防止被檢測為機器人,出現圖片被怪物吃掉了等驗證失敗的情況
action_chains.move_by_offset(-sumOffsetx, 0)
elif dragCount == 3:
# 總誤差值
sumOffsetx = random.randint(-15, 15)
action_chains.move_by_offset(targetOffsetX + sumOffsetx, 0)
# 暫停一會
action_chains.pause(self.__getRadomPauseScondes())
# 已修正誤差的和
fixedOffsetX = 0
# 第一次修正誤差
if sumOffsetx < 0:
offsetx = random.randint(sumOffsetx, 0)
else:
offsetx = random.randint(0, sumOffsetx)
fixedOffsetX = fixedOffsetX + offsetx
action_chains.move_by_offset(-offsetx, 0)
action_chains.pause(self.__getRadomPauseScondes())
# 最后一次修正誤差
action_chains.move_by_offset(-sumOffsetx + fixedOffsetX, 0)
action_chains.pause(self.__getRadomPauseScondes())
else:
raise Exception("莫不是系統出現了問題?!")
action_chains.release().perform()
哇!真的成功啦!完美!















 京公網安備 11010802030320號
京公網安備 11010802030320號