


在機(jī)器學(xué)習(xí)的優(yōu)化問題中,梯度下降法和牛頓法是常用的兩種凸函數(shù)求極值的方法,他們都是為了求得目標(biāo)函數(shù)的近似解。在邏輯斯蒂回歸模型的參數(shù)求解中,一般用改良的梯度下降法,也可以用牛頓法。由于兩種方法有些相似,我特地拿來簡單地對(duì)比一下。
1.梯度下降法
梯度下降法用來求解目標(biāo)函數(shù)的極值。這個(gè)極值是給定模型給定數(shù)據(jù)之后在參數(shù)空間中搜索找到的。
迭代過程為:
梯度下降法更新參數(shù)的方式為目標(biāo)函數(shù)在當(dāng)前參數(shù)取值下的梯度值,前面再加上一個(gè)步長控制參數(shù)alpha。梯度下降法通常用一個(gè)三維圖來展示,迭代過程就好像在不斷地下坡,最終到達(dá)坡底。為了更形象地理解,也為了和牛頓法比較,這里我用一個(gè)二維圖來表示:
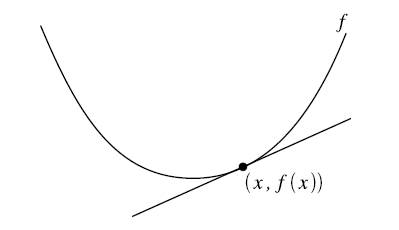
在二維圖中,梯度就相當(dāng)于凸函數(shù)切線的斜率,橫坐標(biāo)就是每次迭代的參數(shù),縱坐標(biāo)是目標(biāo)函數(shù)的取值。
每次迭代的過程是這樣:
首先計(jì)算目標(biāo)函數(shù)在當(dāng)前參數(shù)值的斜率(梯度),然后乘以步長因子后帶入更新公式,如圖點(diǎn)所在位置(極值點(diǎn)右邊),此時(shí)斜率為正,那么更新參數(shù)后參數(shù)減小,更接近極小值對(duì)應(yīng)的參數(shù)。
如果更新參數(shù)后,當(dāng)前參數(shù)值仍然在極值點(diǎn)右邊,那么繼續(xù)上面更新,效果一樣。
如果更新參數(shù)后,當(dāng)前參數(shù)值到了極值點(diǎn)的左邊,然后計(jì)算斜率會(huì)發(fā)現(xiàn)是負(fù)的,這樣經(jīng)過再一次更新后就會(huì)又向著極值點(diǎn)的方向更新。
根據(jù)這個(gè)過程我們發(fā)現(xiàn),每一步走的距離在極值點(diǎn)附近非常重要,如果走的步子過大,容易在極值點(diǎn)附近震蕩而無法收斂。解決辦法:將alpha設(shè)定為隨著迭代次數(shù)而不斷減小的變量,但是也不能完全減為零。
2.牛頓法
首先得明確,牛頓法是為了求解函數(shù)值為零的時(shí)候變量的取值問題的,具體地,當(dāng)要求解 f(θ)=0時(shí),如果 f可導(dǎo),那么可以通過迭代公式,來迭代求得最小值。
通過一組圖來說明這個(gè)過程:
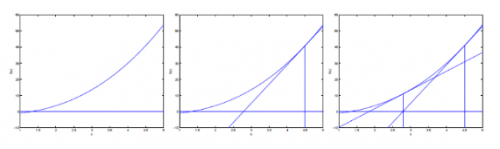
迭代的公式如下:
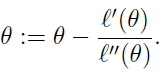
當(dāng)θ是向量時(shí),牛頓法可以使用下面式子表示:
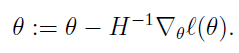
其中H叫做海森矩陣,其實(shí)就是目標(biāo)函數(shù)對(duì)參數(shù)θ的二階導(dǎo)數(shù)。
3.牛頓法和梯度下降法的比較
1.牛頓法:
是通過求解目標(biāo)函數(shù)的一階導(dǎo)數(shù)為0時(shí)的參數(shù),進(jìn)而求出目標(biāo)函數(shù)最小值時(shí)的參數(shù);
收斂速度很快;
海森矩陣的逆在迭代過程中不斷減小,可以起到逐步減小步長的效果。
缺點(diǎn):
海森矩陣的逆計(jì)算復(fù)雜,代價(jià)比較大,因此有了擬牛頓法。
2.梯度下降法:
是通過梯度方向和步長,直接求解目標(biāo)函數(shù)的最小值時(shí)的參數(shù);
越接近最優(yōu)值時(shí),步長應(yīng)該不斷減小,否則會(huì)在最優(yōu)值附近來回震蕩。














 京公網(wǎng)安備 11010802030320號(hào)
京公網(wǎng)安備 11010802030320號(hào)